 Nous présenterons l'Observatoire National des Bâtiments IMOPE, dans le cadre de la journée des données foncières, organisée par la DGALN - Habitat, Urbanisme, Rénovation et le Cerema.
👉 Au menu : présentation des dernières nouveautés et plusieurs annonces importantes ! 📆 Rendez-vous le 22 juin au Ministère de la Transition écologique (Tour Séquoia, La Défense) https://datafoncier.cerema.fr/actualites/journee-nationale-des-donnees-foncieres
0 Commentaires
 Nous sommes ravis de répondre à l'invitation du Cerema pour intervenir à leurs côtés afin de parler des #données au service de l'#innovation verte, ce mardi 21, dans le cadre d'un webinaire Greentech Innovation
👉 https://www.eventbrite.fr/e/billets-mardi-de-la-donnee-cerema-352486044247 La nouvelle feuille de route "intelligence artificielle et transition écologique" du pôle ministériel 2022-2024 vient d’être publiée. Les Ministère de la Transition écologique et Ministère de la Cohésion des territoires sont formels et promeuvent le partage de #données du secteur privé vers le secteur public au service de la #transition #écologique. 🌱🌍
U.R.B.S est fière de faire partie des 4 entreprises identifiées par le gouvernement qui utilisent l’IA pour le diagnostic des #bâtiments à rénover ! ♻️🏡 Nous sommes convaincus que la création de partenariats et de collaborations public/privé est centrale pour obtenir des données et de qualité pour l’élaboration, le pilotage et l’évaluation de politiques de transitions écologique, sociale et énergétique. Nous mettons en place quotidiennement des actions dans ce sens. 👉 Pour en savoir + : https://www.ecologie.gouv.fr/feuille-route-intelligence-artificielle-et-transition-ecologique 👉 Texte complet : https://lnkd.in/eTkayq4q  La base des diagnostics de performance énergétique (DPE) publiée par l'ADEME en 2021 donne lieu à des spéculation diverses à cause d'un phénomène facilement observable sur le graphique joint. Que se passe-t-il à la frontière entre l'étiquette E et l'étiquette F ? (voir graphique en fin d'article) La valeur 330 pour la consommation d'énergie est une valeur réglementaire (limite entre 2 étiquettes) qui modifie les comportements. On parle d'un "effet de seuil". Un autre effet de seuil bien connu est celui des minima sociaux : certaines personnes renoncent à une augmentation de salaire pour ne pas perdre des aides sociales, ce qui entraînerait finalement une baisse de leurs revenus. Pour éviter ce type de phénomène, l'Etat met parfois en place des mesures de "lissage" en introduisant par exemple une série de seuils intermédiaires. Qu'est-ce qui peut pousser le diagnostiqueur à modifier son comportement à l'approche du seuil pour favoriser, dans notre cas l'étiquette E par rapport à l'étiquette F ? Le diagnostiqueur se comporte, toutes proportions gardées, un peu comme un médecin qui dit à son patient que tout va bien se passer alors qu'il sait que ses chances de survie sont faibles. Le diagnostiqueur dit au propriétaire, ne vous inquiétez pas, votre logement n'est pas en si mauvais état, alors qu'il sait que le logement risque bien d'être prochainement interdit à la location. Justement, à quoi est attribué ce comportement quand ils vient des médecins ? On parle généralement de l'empathie du soignant. Or dans le cas de la médecine, l'empathie et l'optimisme qui va avec, sont aujourd'hui encouragés car on sait qu'ils aident à la guérison. Est-il possible que les diagnostiqueurs soient empathique ? Est-ce qu'un propriétaire d'un logement qui consomme 329kWh/m/an serait encouragé à rénover pour ne pas basculer de l'autre côté de la frontière ? Cela relève d'une étude sociologique qui n'existe pas (pas encore ?). Mais en tous cas, tout c'est très différent de la fraude. Cet effet de seuil est quand même gênant pour les statisticiens car il modifie le décompte des passoires thermiques (étiquettes F et G). Dans un article récemment publié en ligne (https://www.energy-alternatives.eu/2021/11/10/DPE-passoires.html), les effets de seuils sont attribués à la fraude et les auteurs modifient la distribution en publiant un décompte des passoires thermiques légendé "La correction des fraudes a un impact essentiel." Cependant, le diagnostic immobilier n'est pas une "science objective", il est fait par des humains, pour des humains, avec des variables observables et d'autres qui ne le sont pas. Et, on l'a vu, un effet de seuil n'est pas nécessairement une fraude. Est-ce que la fraude avérée est observable dans la base DPE ? Oui. Or, en général, elle ne se joue pas sur 3kWh/m²/an mais sur bien plus. Par exemple, on trouve des maisons construites après 1948 avec un mauvais DPE (E ou F) qui sont re-diagnostiquées 15 jours plus tard avec une année de construction 1947 et un super DPE. Les spécialistes reconnaîtront là une intention avérée de détourner la législation : les diagnostics des logement construits avant 1948 étant réalisés (à l'époque) sur facture, ils peuvent se retrouver en A ou B si le logement était vacant l'année précédente. Ici, on peut suivre pas à pas le processus et on voit que les paramètres de calculs ont été sciemment modifiés. C'est différent d'un effet de seuil. En conclusion, rappelons que le DPE est un outil important dans la politique d'amélioration du logement. Il serait risqué de le discréditer en invoquant une fraude massive. Si les effets de seuil sont avant tout un révélateur d'humanité, doit-on s'en plaindre ? Marc Grossouvre (Data Scientist - Ingénieur en mathématiques, U.R.B.S) 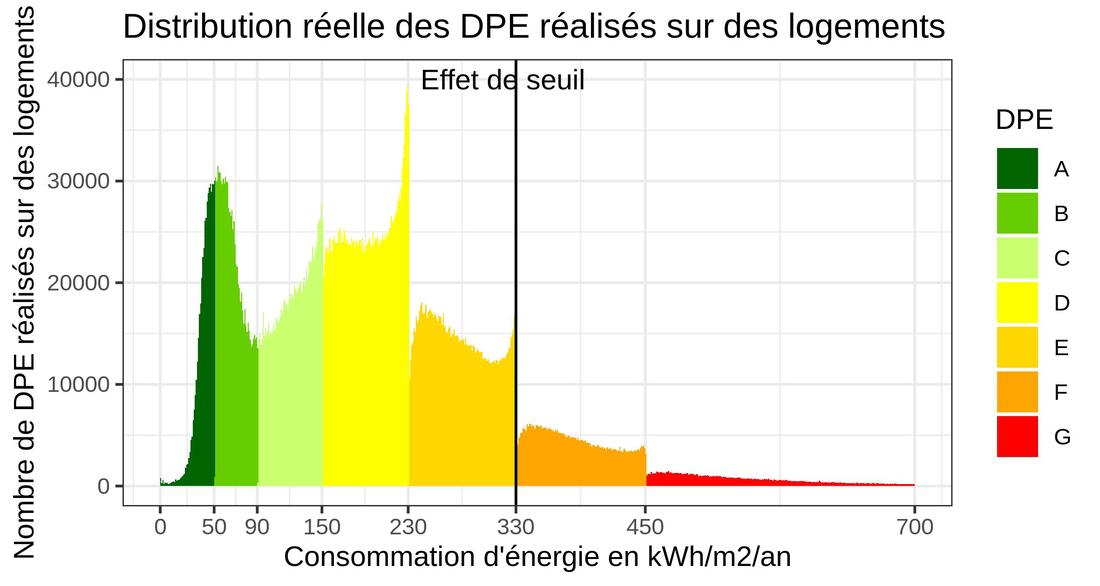 Un podcast très bien réalisé qui explique les travaux de U.R.B.S, nos liens avec la recherche, l’innovation, la transition énergétique et le numérique. Au micro, notre expert scientifique (et co-fondateur), Jonathan Villot !   Pour une parfaite prise en compte du végétal dans les PLUi et une optimisation des prescriptions d’urbanisme, il est indispensable pour les acteurs publics de disposer d'une vision fine du patrimoine végétalisé 🌱 et arboré 🌳. Sur le territoire de l'Agglomération du Grand Annecy et en collaboration avec l'École des Mines de Saint-Étienne nous avons déployé des outils innovants de caractérisation du végétal (#CANOPÉE)
Ces travaux sur la végétation intègrent : - Des visuels à très haute résolution 🎯 (0,2 m²) de la végétation par strates arbustives - Le repérage à l'unité 📌 (approche objet) de plus de 330 000 arbres 🌳 sur la tâche urbaine - La caractérisation de plusieurs milliers d'arbres : division (🌲Vs🌳 ) / Genre (Tilleuls, platanes, ...) / Hauteur, diamètre du houppier - L'appariement à plusieurs bases de données 🌐 (SESAME Cerema), données locales du territoire (arbres en alignement, ...) Ce travail innovant 👊 et documenté (fiches méthodologiques, limite et fiabilité des résultats, ....) se base sur une expertise de haut niveau, des algorithmes performants 🛠️ (deep et machine learning), et des données de qualité (images aériennes et satellites 🛰️ + Lidar). Données rendues accessibles par des acteurs engagés IGN (Institut national de l'information géographique et forestière) ✅ To be continued : ces travaux réplicables à tous les territoires, s'inscrivent dans un projet de grande ampleur amorcé par le Grand Annecy. Ils seront prochainement complétés (Mai 2022) par une caractérisation à maille fine et à large échelle des ICU 🌡️ (#SIRIUS) ainsi que d'indicateurs, à l'adresse, permettant d'aborder la question de la vulnérabilité du parc bâti 🏘️ aux vagues de chaleur et aux effets du #réchauffementclimatique
Quelques chiffres clefs sur la région Pays de Loire et un cas d’usage à Angers 📍
👉 Être un mouton de Panurge de l’IA
1. Faire comme la concurrence ou comme le service de l’étage en dessous : ils ont un truc avec TensorFlow, il nous en faut un aussi. Pour faire quoi ? On verra plus tard… 1bis. Faire comme dans 1 avec n’importe quelle technologie de Machine Learning, Big Data, Cloud ou IoT à la place de TensorFlow. Vous avez le droit de cumuler les technologies « à la mode » pour rater un projet. 👉 Ne jamais se demander pourquoi on fait de l’IA 2. Ne pas impliquer le métier : ne pas solliciter l’avis des futurs utilisateurs, ne pas leur demander ce qu’ils veulent ni pourquoi ils le veulent. Bref, tout mettre en œuvre pour créer des algorithmes hors sol, qui ne servent à rien ni à personne. 3. Si vous avez quand même demandé l’avis du métier (après tout, vous avez le droit d’essayer de réussir votre projet) et que des aspects fonctionnels essentiels sont trop compliqués à prendre en compte dans un POC, il ne faut pas hésiter à les supprimer. L’essentiel c’est de faire rapidement un POC, et non qu’il soit réaliste ni qu’il prouve un ROI. 👉 Un stagiaire peut-il sauver le monde ? 4. Donner à un stagiaire deux feuilles Excel et un code Python non documenté, réalisé il y a deux ans par un stagiaire précédent. Et attendre qu’il produise de la valeur pour l’entreprise… 👉 Pourquoi faire simple quand on peut faire compliqué ? 5. Architecturer du Big Data parce qu’il nous faut absolument du NoSQL, du Hadoop… Et finir par se noyer dans le Data Lake parce qu’on a oublié qu’il vaut toujours mieux s’assurer que ça fonctionne en Small avant de penser Big. 👉 Écouter les faux experts 6. Faire tout tout seul en interne parce que Bob nous a parlé d’une librairie Python open source et gratuite qu’il avait déjà utilisée. Bob avait juste oublié de nous dire que ce qu’il considérait comme « utiliser une librairie Python », c’était la télécharger et jouer quinze minutes avec les exemples fournis. 7. Écrire ces 6 lignes de code Python et se dire : « Ça y est, je suis Data Scientist ». 👉 Au fait, les données, elles sont où ? Tu es sûr que ce sont les bonnes ? 8. Faire des POC dans un notebook, puis, en fonction du résultat, refaire un POC dans un autre notebook et continuer à dépenser sans compter, sans se préoccuper de l’intégration informatique ni de la gestion des flux de données : on pensera au déploiement quand on fera le déploiement. C’est la version disruptive et innovante de « c’est au pied du mur qu’on voit mieux le mur ». 9. Donner trois images de chiens en entrée d’un réseau de neurones et se demander pourquoi il ne reconnaît pas les chats. 10. Élaborer un super pipeline avec des algorithmes ultra-optimisés et ultrasophistiqués (même que j’ai fait un gridsearch !) … Puis se rendre compte que l’on n’aura jamais accès aux données. 👉 L’IA, c’est le Machine Learning ! 11. Appliquer l’IA Connexionniste et le Machine Learning à tous les sujets d’IA et d’aide à la décision (même ceux pour lesquels ces technologies ne sont pas adaptées) : ne surtout pas connaître ni utiliser les statistiques « old school », l’IA Symbolique, les systèmes-experts, les BRMS, le Prolog, les systèmes multi-agents, la Recherche Opérationnelle, l’Optimisation, la Programmation Linéaire, la Programmation Par Contraintes, les Méta-Heuristiques … 👉 IA plutôt intelligente ou artificielle ? 12. Croire que l’IA est intelligente : elle est surtout artificielle, mais peut être très utile quand elle est bien utilisée. Ce qui est intelligent, c’est le recueil des données, la modélisation, le codage d’algorithmes, le paramétrage de ces modèles et d’algorithmes. Et c’est effectué par des humains … 🔗 https://www.eurodecision.com/algorithmes/intelligence-artificielle/comment-planter-projet-ia |
Archives
Octobre 2023
|



 Flux RSS
Flux RSS