👉 Être un mouton de Panurge de l’IA
1. Faire comme la concurrence ou comme le service de l’étage en dessous : ils ont un truc avec TensorFlow, il nous en faut un aussi. Pour faire quoi ? On verra plus tard… 1bis. Faire comme dans 1 avec n’importe quelle technologie de Machine Learning, Big Data, Cloud ou IoT à la place de TensorFlow. Vous avez le droit de cumuler les technologies « à la mode » pour rater un projet. 👉 Ne jamais se demander pourquoi on fait de l’IA 2. Ne pas impliquer le métier : ne pas solliciter l’avis des futurs utilisateurs, ne pas leur demander ce qu’ils veulent ni pourquoi ils le veulent. Bref, tout mettre en œuvre pour créer des algorithmes hors sol, qui ne servent à rien ni à personne. 3. Si vous avez quand même demandé l’avis du métier (après tout, vous avez le droit d’essayer de réussir votre projet) et que des aspects fonctionnels essentiels sont trop compliqués à prendre en compte dans un POC, il ne faut pas hésiter à les supprimer. L’essentiel c’est de faire rapidement un POC, et non qu’il soit réaliste ni qu’il prouve un ROI. 👉 Un stagiaire peut-il sauver le monde ? 4. Donner à un stagiaire deux feuilles Excel et un code Python non documenté, réalisé il y a deux ans par un stagiaire précédent. Et attendre qu’il produise de la valeur pour l’entreprise… 👉 Pourquoi faire simple quand on peut faire compliqué ? 5. Architecturer du Big Data parce qu’il nous faut absolument du NoSQL, du Hadoop… Et finir par se noyer dans le Data Lake parce qu’on a oublié qu’il vaut toujours mieux s’assurer que ça fonctionne en Small avant de penser Big. 👉 Écouter les faux experts 6. Faire tout tout seul en interne parce que Bob nous a parlé d’une librairie Python open source et gratuite qu’il avait déjà utilisée. Bob avait juste oublié de nous dire que ce qu’il considérait comme « utiliser une librairie Python », c’était la télécharger et jouer quinze minutes avec les exemples fournis. 7. Écrire ces 6 lignes de code Python et se dire : « Ça y est, je suis Data Scientist ». 👉 Au fait, les données, elles sont où ? Tu es sûr que ce sont les bonnes ? 8. Faire des POC dans un notebook, puis, en fonction du résultat, refaire un POC dans un autre notebook et continuer à dépenser sans compter, sans se préoccuper de l’intégration informatique ni de la gestion des flux de données : on pensera au déploiement quand on fera le déploiement. C’est la version disruptive et innovante de « c’est au pied du mur qu’on voit mieux le mur ». 9. Donner trois images de chiens en entrée d’un réseau de neurones et se demander pourquoi il ne reconnaît pas les chats. 10. Élaborer un super pipeline avec des algorithmes ultra-optimisés et ultrasophistiqués (même que j’ai fait un gridsearch !) … Puis se rendre compte que l’on n’aura jamais accès aux données. 👉 L’IA, c’est le Machine Learning ! 11. Appliquer l’IA Connexionniste et le Machine Learning à tous les sujets d’IA et d’aide à la décision (même ceux pour lesquels ces technologies ne sont pas adaptées) : ne surtout pas connaître ni utiliser les statistiques « old school », l’IA Symbolique, les systèmes-experts, les BRMS, le Prolog, les systèmes multi-agents, la Recherche Opérationnelle, l’Optimisation, la Programmation Linéaire, la Programmation Par Contraintes, les Méta-Heuristiques … 👉 IA plutôt intelligente ou artificielle ? 12. Croire que l’IA est intelligente : elle est surtout artificielle, mais peut être très utile quand elle est bien utilisée. Ce qui est intelligent, c’est le recueil des données, la modélisation, le codage d’algorithmes, le paramétrage de ces modèles et d’algorithmes. Et c’est effectué par des humains … 🔗 https://www.eurodecision.com/algorithmes/intelligence-artificielle/comment-planter-projet-ia
0 Commentaires
Nous sommes ravis de mettre notre solution IMOPE à disposition de nouveaux territoires, parmi lesquels la Métropole Européenne de Lille, la Ville de Roubaix, l’ETP Plaine Commune, la Ville de Saint-Denis, … ainsi qu’à leurs AMO, agences d’urbanisme ou encore DDT, pour faciliter des études pré-opérationnelle et élaborations d’OPAH-RU ! ♻️🏘 #IMOPE est l’observatoire national des bâtiments au service des décideurs ET des opérationnels des territoires. Son rôle est simple : produire des données qualifiées, complètes, multi-thématiques et permettre la compréhension et leur manipulation, au service de la transition énergétique, solidaire et numérique des territoires ! 🌱🌎 La collaboration sur ces différents territoires a permis de faire émerger une connaissance complète, fine et fiabilisée en croisant une multitude de données nationales, locales et d’observations terrain, sous la forme d’une base de donnée géographique standardisée, à l’échelle du bâtiment, accessible facilement depuis notre outil IMOPE. ⚙️🗺 Ce travail inédit en France de croisements de données et d'utilisation en contexte opérationnel démontre de l'intérêt de la #data au service des #territoires ! IMOPE vous intéresse ? Contactez-nous 👉 [email protected] 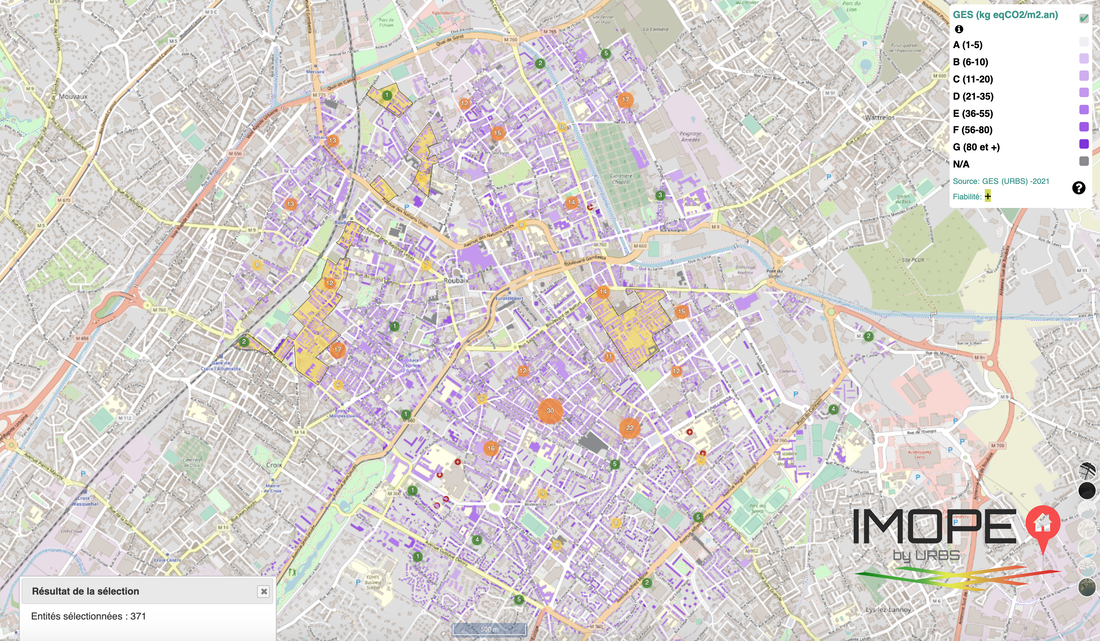 |
Archives
Octobre 2023
|

 Flux RSS
Flux RSS